今回もカロリー記録システムの開発記録である。
実は本日2本目の記事となる。なんとなく筆が乗ったというか、vimが乗ったというか、一気に開発を進めてしまった。
前回はカロリーをグラフ表示させるためのmatplotlib出力部分を作った。
thom.hateblo.jp
今回はこのグラフにデータを受け渡す部分。恐らく今回の開発で最難関になるだろう部分に取り組んだ。
pandasというライブラリでcsvからデータを読み取ってごにょごにょするんだけど、そのごにょごにょが凄く難しい。
単にpandasに慣れ親しんでいないためというのもあるけど、前回も体重記録を使えるデータに変換するのに大変に苦労した覚えがある。
コード
import pandas as pd import numpy as np import matplotlib.pyplot as plt from datetime import datetime, date, timedelta df = pd.read_csv("/home/pi/calorie.csv", header=None, names=["timestamp","meal_type", "calorie"], parse_dates=["timestamp"]) print('\n--print dataframe which generated from csv--') print(df) dummy_data = [] for i in range(0, 7)[::-1]: for meal in ["Breakfast","Lunch","Dinner"]: sublist = [] sublist.append((datetime.now()-timedelta(days=i))) sublist.append(meal) sublist.append(0) dummy_data.append(sublist) dummy_columns = ["timestamp","meal_type","calorie"] dummy_df = pd.DataFrame(data=dummy_data,columns=dummy_columns) print('\n--print dummy dataframe for data completeness--') print(dummy_df) df = df.append(dummy_df,ignore_index=True) df["date"] = df["timestamp"].dt.strftime("%Y-%m-%d") df = df.groupby(["date","meal_type"]).agg({"calorie":"sum"}).reset_index() print('\n--print completed data--') print(df) df = df.pivot_table(index="date", columns="meal_type", values="calorie") print('\n--print pivot data--') print(df) print('\n--print tailed data--') df = df.tail(7) print(df) record_date = [datetime.strptime(d,"%Y-%m-%d").strftime("%m/%d") for d in df.index] minimum = np.array([1600 for i in df.index]) breakfast = df["Breakfast"].values lunch = df["Lunch"].values dinner = df["Dinner"].values maximum = np.array([2400 for i in df.index]) plt.title("Calorie Record", fontsize = 22) plt.xlabel("Date", fontsize = 22) plt.ylabel("Calorie", fontsize = 22) plt.grid(True) plt.bar(record_date, maximum-minimum, width=0.25, bottom = minimum, tick_label = record_date, align="center", label="Guideline", color = "#98fb98", edgecolor="#008000", lw=0, hatch="/////") plt.bar(record_date, breakfast, width=0.2, tick_label = record_date, align="center", label="Breakfast", color = "#f3d394") plt.bar(record_date, lunch, width=0.2, bottom = breakfast, tick_label = record_date, align="center", label="Lunch", color = "#45938b") plt.bar(record_date, dinner, width=0.2, bottom = breakfast+lunch, tick_label = record_date, align="center", label="Dinner", color = "#003a34") #plt.legend(loc="upper right", fontsize=10) plt.show()
決して褒められたコードではない。しかしなんとか動いたのでこれが今の限界。
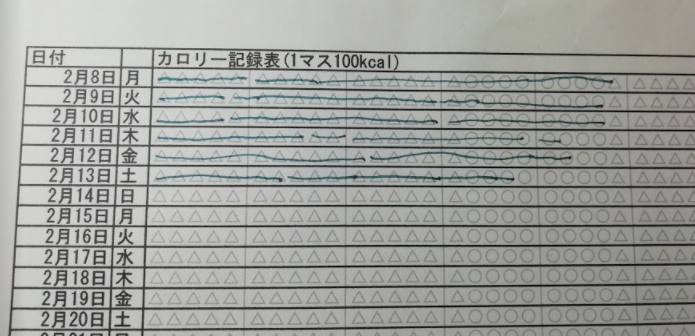
動作イメージ
今日書いた別の記事と同じなので変わり映えしないけど、しいて言えば今日から電子的な記録を始めた実データを使った関係で前日までのデータは空っぽである。
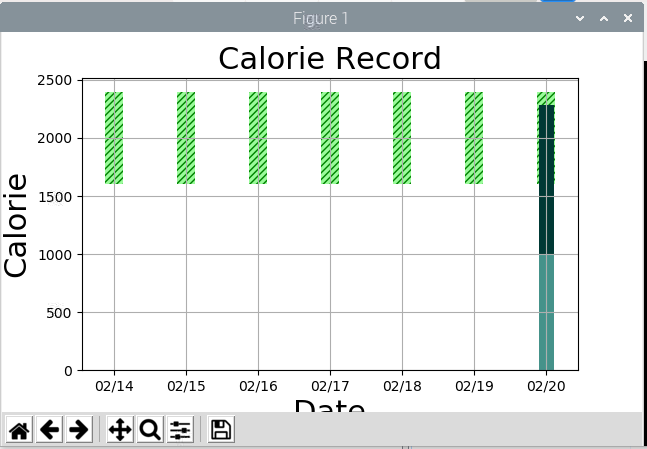
※朝ごはん(薄橙)が無いのは今朝クリニックで検査があった関係で食べてない為。
動作の詳細説明
このコードはデータが加工されていくそれぞれのステップでprintするように作っているので、そのステップごとのprint結果と何をしているのかを解説していく。
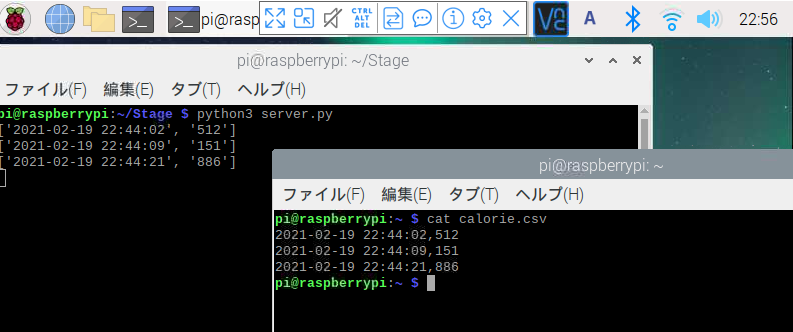
1) CSVから実際に記録されたカロリーデータを取得する
これは実データを読み込んでpandasライブラリのデータフレームという型になったものをprintしている。
--print dataframe which generated from csv--
timestamp meal_type calorie
0 2021-02-20 12:22:37 Lunch 498
1 2021-02-20 12:22:48 Lunch 51
2 2021-02-20 12:23:03 Lunch 456
3 2021-02-20 17:58:05 Dinner 84
4 2021-02-20 17:58:16 Dinner 321
5 2021-02-20 17:58:27 Dinner 108
6 2021-02-20 17:58:38 Dinner 765
2) 不足データを補完するためのダミーデータ作成
実データと同じ形式のDataFrameを過去7日分、それぞれBreakfast・Lunch・Dinnerを用意し、カロリーは0としておく。
集計されたときに項目の欠落を防止しつつ、実データと同じ日付でもカロリーに影響を与えない。
--print dummy dataframe for data completeness--
timestamp meal_type calorie
0 2021-02-14 23:11:14.317393 Breakfast 0
1 2021-02-14 23:11:14.317469 Lunch 0
2 2021-02-14 23:11:14.317488 Dinner 0
3 2021-02-15 23:11:14.317507 Breakfast 0
4 2021-02-15 23:11:14.317524 Lunch 0
5 2021-02-15 23:11:14.317541 Dinner 0
6 2021-02-16 23:11:14.317559 Breakfast 0
7 2021-02-16 23:11:14.317576 Lunch 0
8 2021-02-16 23:11:14.317593 Dinner 0
9 2021-02-17 23:11:14.317611 Breakfast 0
10 2021-02-17 23:11:14.317628 Lunch 0
11 2021-02-17 23:11:14.317644 Dinner 0
12 2021-02-18 23:11:14.317662 Breakfast 0
13 2021-02-18 23:11:14.317679 Lunch 0
14 2021-02-18 23:11:14.317696 Dinner 0
15 2021-02-19 23:11:14.317713 Breakfast 0
16 2021-02-19 23:11:14.317729 Lunch 0
17 2021-02-19 23:11:14.317746 Dinner 0
18 2021-02-20 23:11:14.317764 Breakfast 0
19 2021-02-20 23:11:14.317778 Lunch 0
20 2021-02-20 23:11:14.317793 Dinner 0
3) 実データのDataFrameとダミーのDataFrameを結合した後、dateとmeal_typeでグルーピング
--print completed data--
date meal_type calorie
0 2021-02-14 Breakfast 0
1 2021-02-14 Dinner 0
2 2021-02-14 Lunch 0
3 2021-02-15 Breakfast 0
4 2021-02-15 Dinner 0
5 2021-02-15 Lunch 0
6 2021-02-16 Breakfast 0
7 2021-02-16 Dinner 0
8 2021-02-16 Lunch 0
9 2021-02-17 Breakfast 0
10 2021-02-17 Dinner 0
11 2021-02-17 Lunch 0
12 2021-02-18 Breakfast 0
13 2021-02-18 Dinner 0
14 2021-02-18 Lunch 0
15 2021-02-19 Breakfast 0
16 2021-02-19 Dinner 0
17 2021-02-19 Lunch 0
18 2021-02-20 Breakfast 0
19 2021-02-20 Dinner 1278
20 2021-02-20 Lunch 1005
4) meal_typeを列としてピボット集計する
--print pivot data-- meal_type Breakfast Dinner Lunch date 2021-02-14 0 0 0 2021-02-15 0 0 0 2021-02-16 0 0 0 2021-02-17 0 0 0 2021-02-18 0 0 0 2021-02-19 0 0 0 2021-02-20 0 1278 1005
5) 過去7日分だけ取り出す。
今回は実データが本日分しかないので加工結果は変わらない。
もしそれ以上のデータがあるとダミーもその分用意したり、グラフが細くなって見づらくなったりする。
--print tailed data-- meal_type Breakfast Dinner Lunch date 2021-02-14 0 0 0 2021-02-15 0 0 0 2021-02-16 0 0 0 2021-02-17 0 0 0 2021-02-18 0 0 0 2021-02-19 0 0 0 2021-02-20 0 1278 1005
6) numpyのndarray形式でそれぞれの列を抜き出してmatplotlibでplotする
ここは特に画面出力とかはしていない。
本当はDataFrameのままmatplotlibで出力する方法があるんだろうけど、前回の記事でnumpyのndarray形式をPlotするやり方の実績があるのでとりあえずデータを前回と同様の方式に合わせた。
CSVにカロリーを記録するプログラムの変更
以前書いたこちらの記事であるが、今回のプログラム作成にあたりこちらも変更した。
thom.hateblo.jp
これまで生のタイムスタンプだけ残してて、pandasで集計するときに時間によって朝食・昼食・夕食に分ければいいやと思ってたんだけど。。
そもそもデータ受信時に判定させて、一緒に記録しといたら楽なんじゃね?ということに気づいて改善。
カロリー記録時間をベースに以下の判定基準とした。
0時~11時:朝飯
11時~17時:昼飯
17時~24時:晩飯
深夜1時に何か食べるのが朝飯かと言われると微妙なんだが、当日の2時までは前日の晩飯扱いとかプログラム的に面倒なので。
一応コードも載せておこう。ブログに書いとけばぶっ飛んでも安心。(GitHub使えよといわれそうだけど。。)
import socket import time import csv import os from datetime import datetime def meal_type(timestamp): if 0 <= timestamp.hour <= 10: return "Breakfast" elif 11 <= timestamp.hour <= 16: return "Lunch" else: return "Dinner" def record_calorie(cal): file_path = '/home/pi/calorie.csv' with open(file_path,'a',newline='') as f: w = csv.writer(f) timestamp = datetime.now() w.writerow([timestamp.strftime('%Y-%m-%d %H:%M:%S'), meal_type(timestamp), cal]) print([timestamp.strftime('%Y-%m-%d %H:%M:%S'), meal_type(timestamp) ,cal]) with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind(("", 49152)) while True: s.listen(1) conn, addr = s.accept() try: data = conn.recv(16).decode('utf8') record_calorie(data) time.sleep(1) except socket.error: pass except KeyboardInterrupt: conn.close() s.close() conn.close()
おわりに
pandas、numpy、matplotlibはどれも非常に有用なツールであるが、私にとってはどれも非常に難しく感じる。
書籍が充実してなくて基本ネットで調べるしかないが、公式を当たると表記が専門的で難しく、有志のサイトを当たっても基礎知識がない状態でサンプルを見よう見まねで手探りで作っている状態だ。
でも以前に体重データ集計する際に使ったときよりは、pandasデータフレームについてずいぶん理解が進んだ気がする。
さて、今のところ摂取カロリー目安は固定にしているが、たぶん3か月もすればこの基準値では痩せなくなる。なぜなら体重の減少と同時に消費カロリーも減少するため。
そのあたりの計算は以下の記事で書いた。
thom.hateblo.jp
なので、次は摂取カロリー目安を体重記録と連動させて計算によって上下させる機能を追加したい。
あとはこのグラフをtkinterに埋め込むのと、カロリーデータ受信時に自動でグラフが起動するようにしたい。
既に運用でカバーできるくらいのところまでは作れたので、2月中はM5 Stackでの電子記録と紙記録を併用して、3月からは完全に電子記録に切り替えようと思う。
とりあえず、今回はここまで。

")