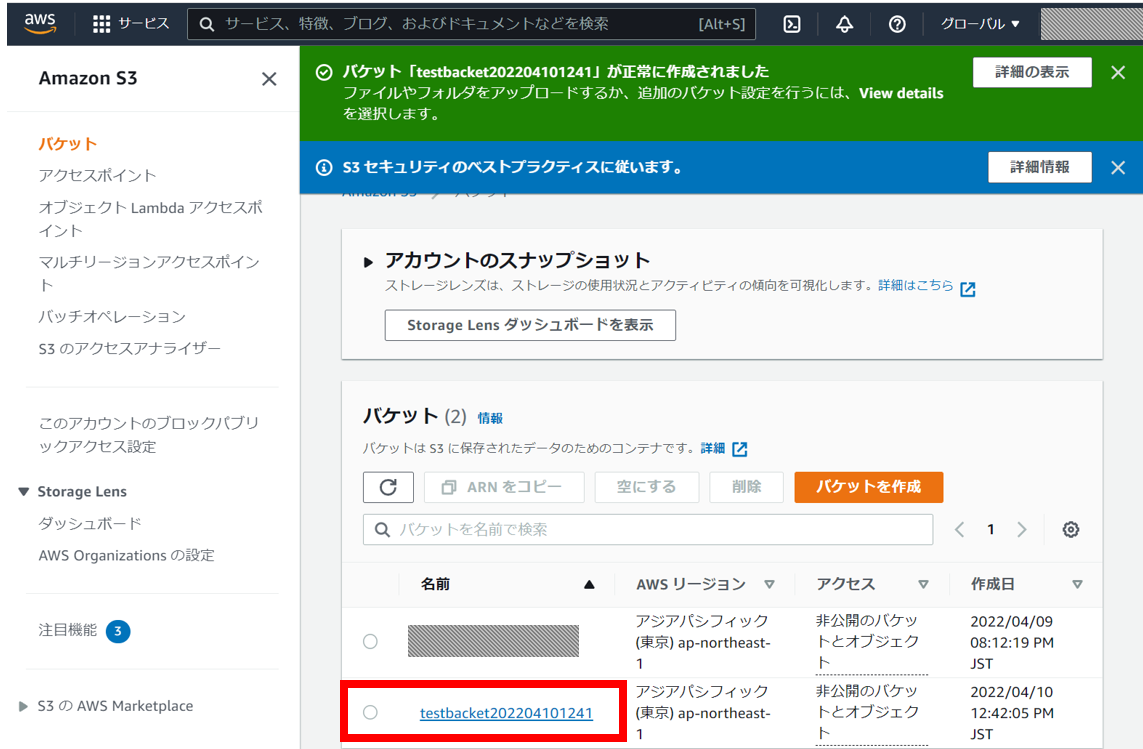
今回はAmazon AWS S3とSambaサーバーを組み合わせて、とりいそぎ使えそうなアーカイブソリューションが構築できたのでご紹介。
めったに参照しないけど無くなると困るファイルを、安全かつ恒久的にアーカイブする。
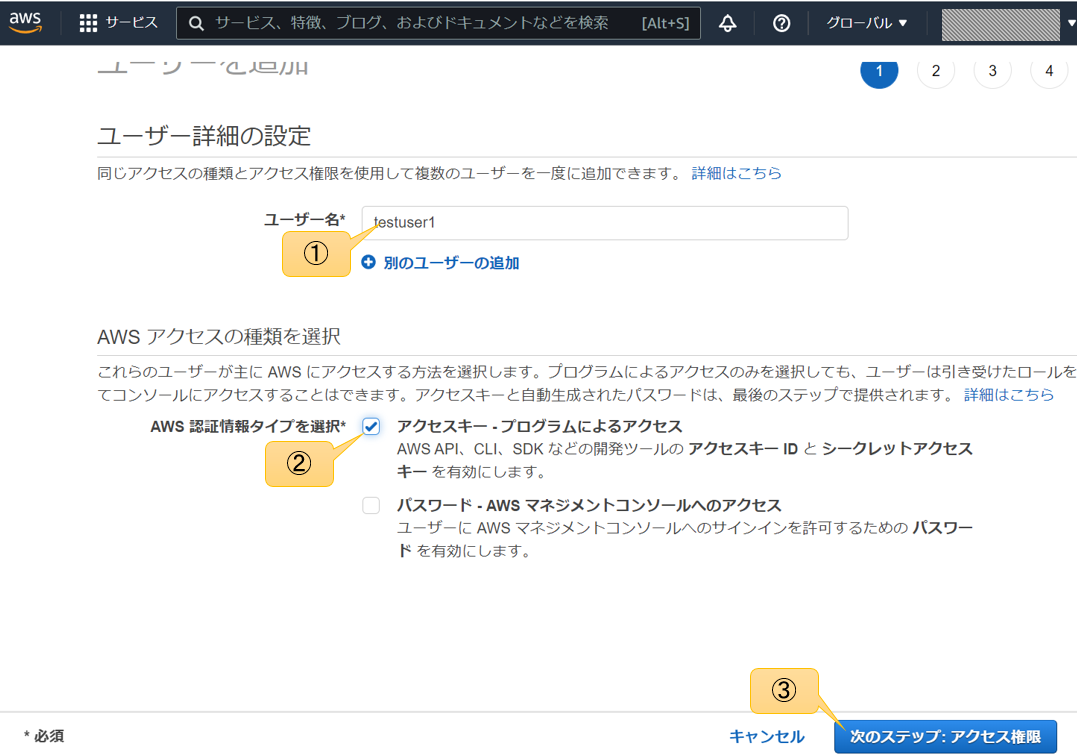
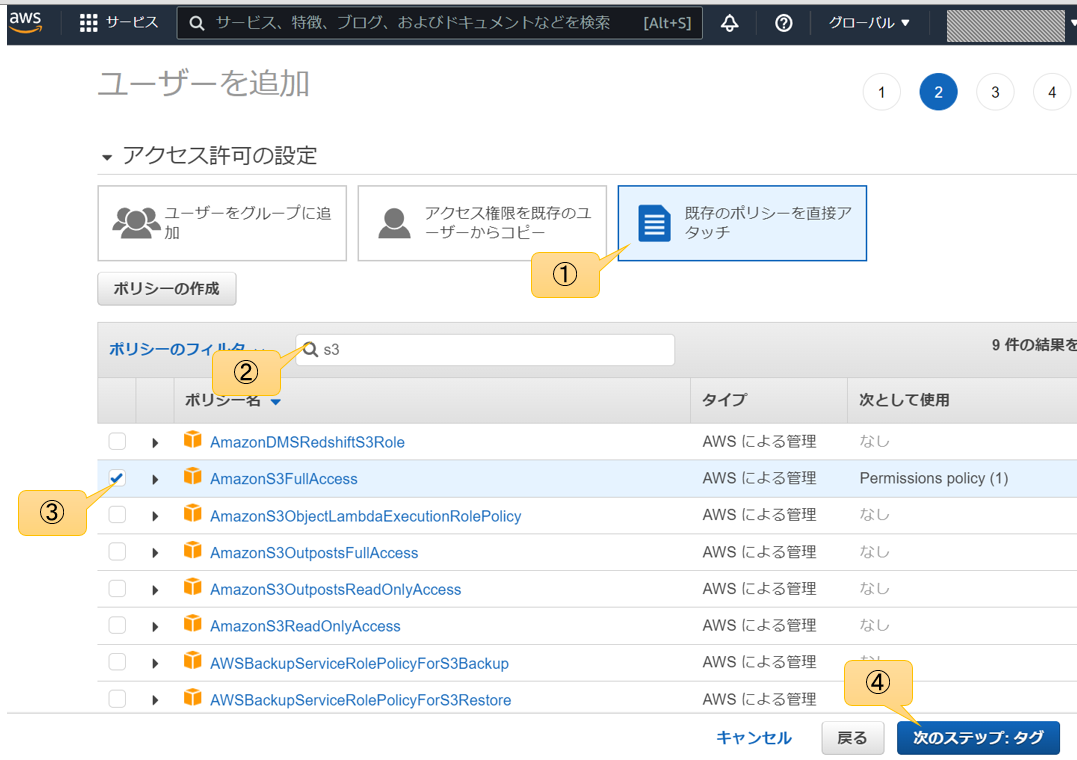
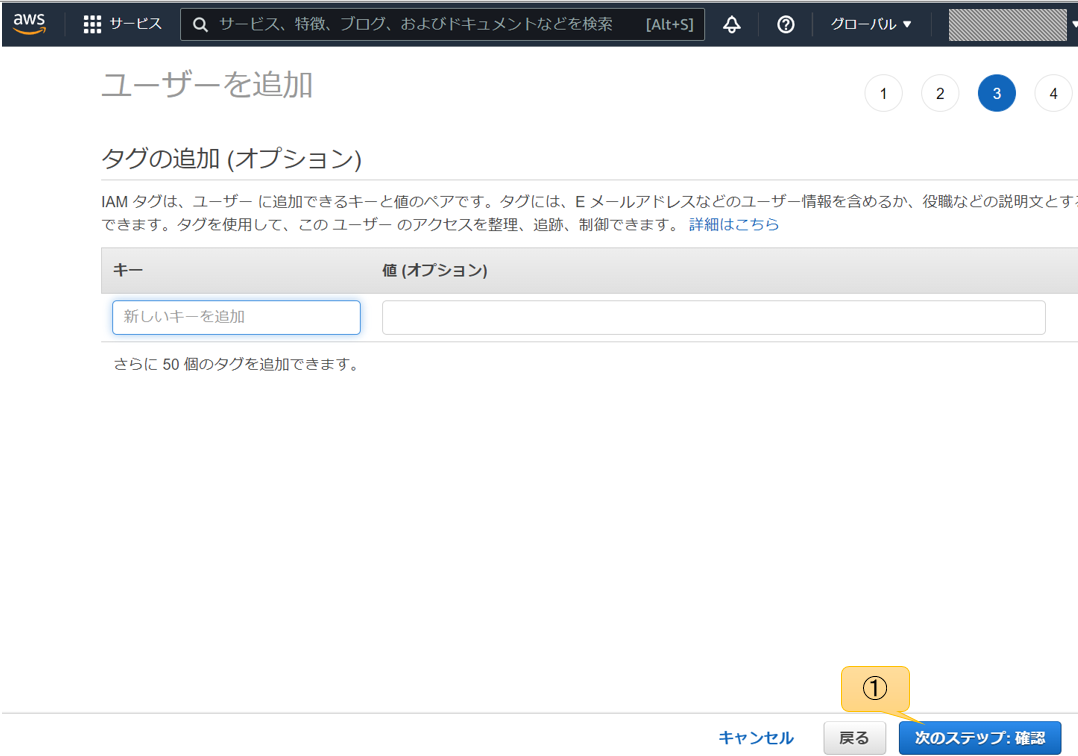
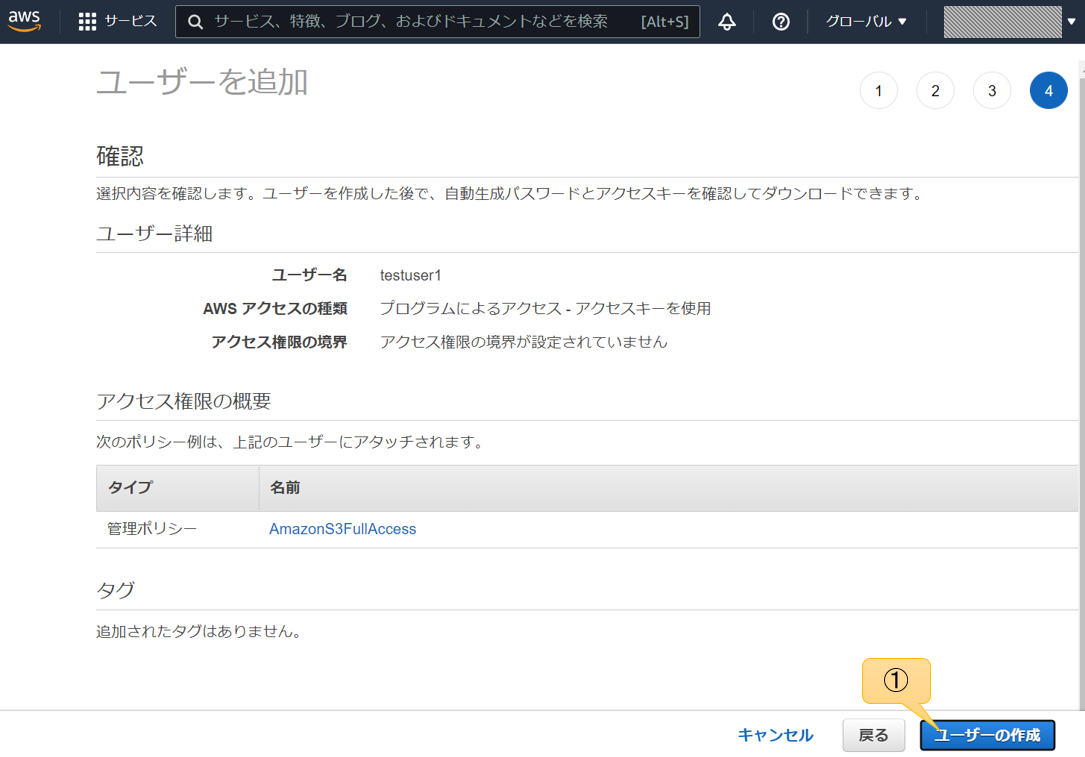
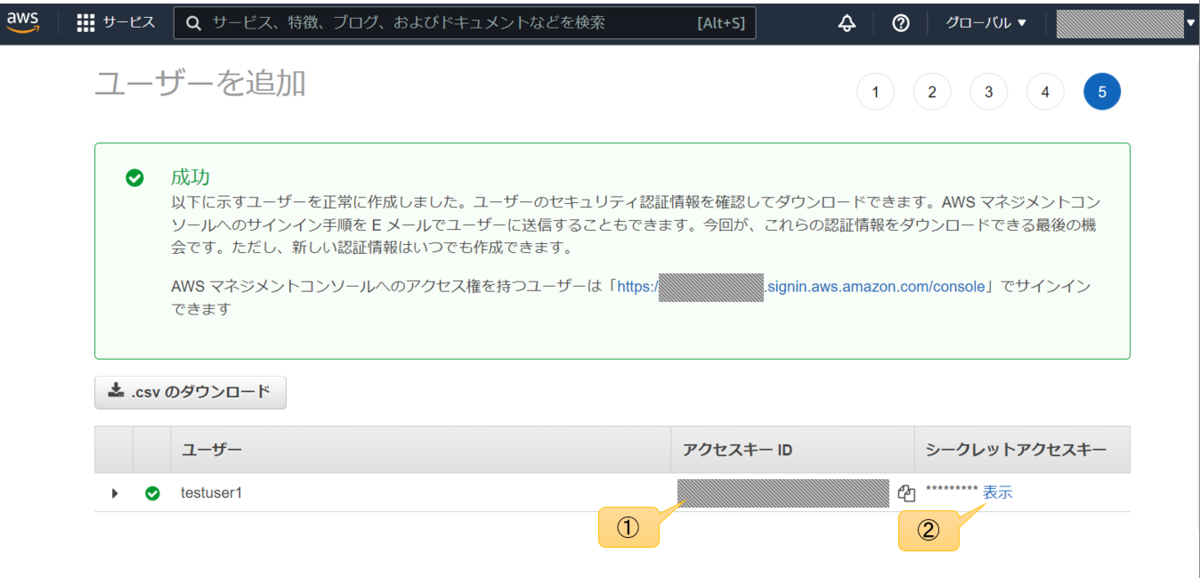
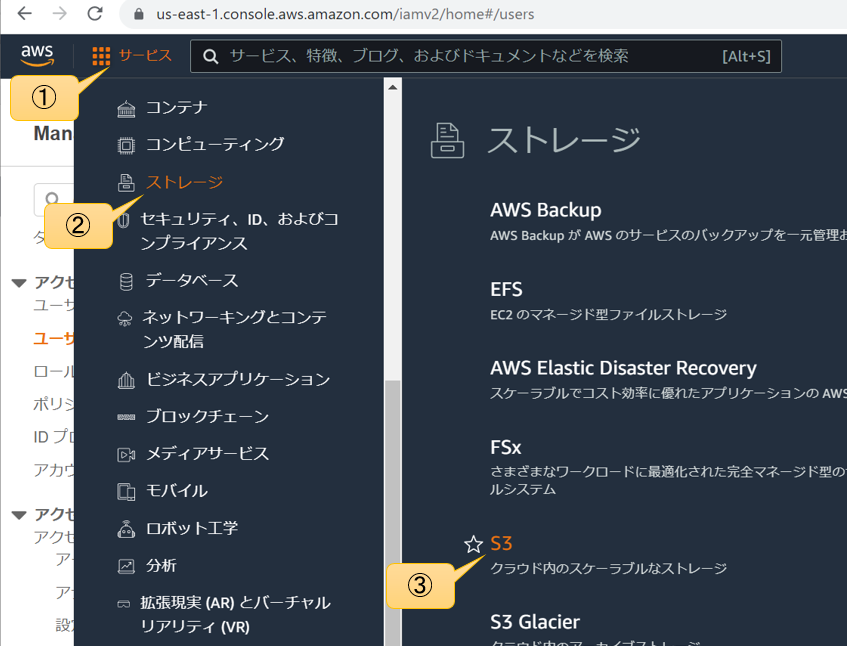
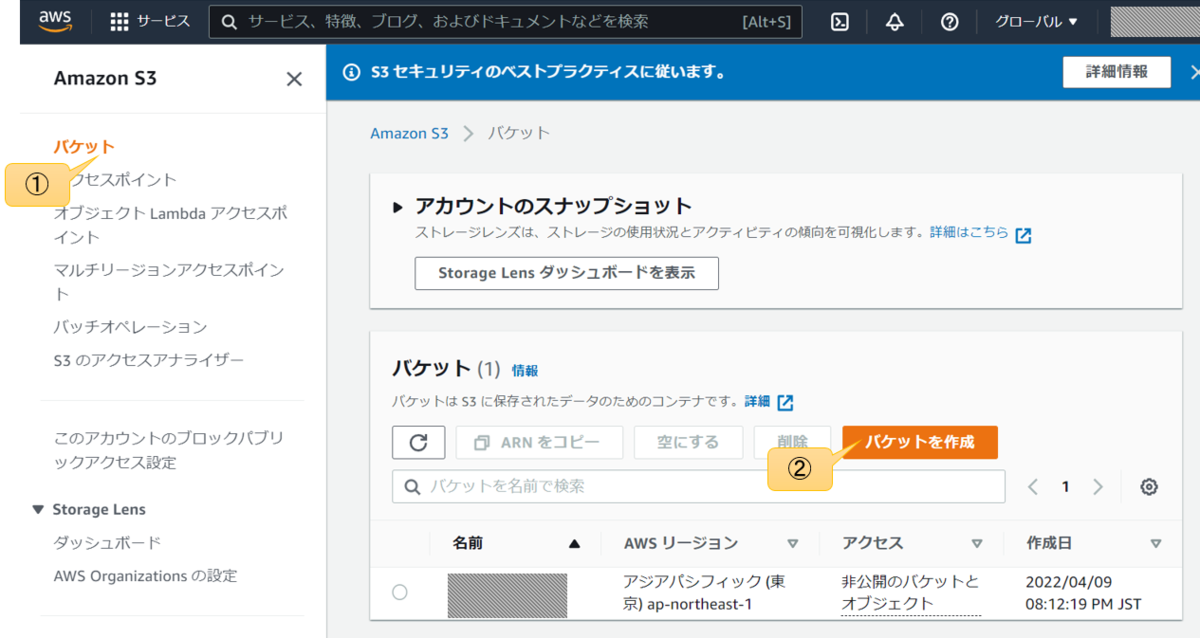
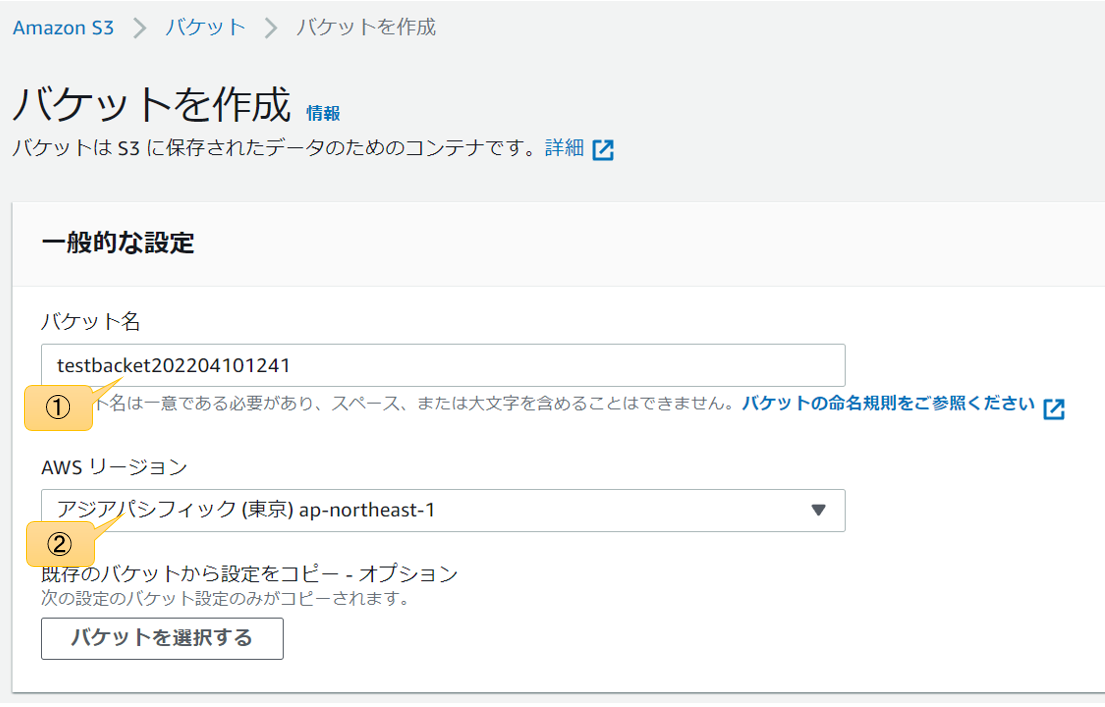
概要と使い方
仕組みを説明したのが以下の図。

- Sambaサーバー上にあるToArchiveというフォルダーに大事なファイルを配置する。
- cronジョブにより実行されるバッチがToArchive内のファイルをAmazon S3へアップロードする
- 上記バッチはアップロードが完了したローカルファイルをSambaサーバー上のArchiveフォルダへ移動する。
この仕組みのメリットは図上の吹き出し参照。
特にファイルを間違って消しそうになっても、Archiveフォルダは書き込みアクセス権が無くて弾いてくれるのがありがたい。
各種設定
/etc/samba/smb.conf
[global]
dos charset = CP932
unix charset = UTF-8
workgroup = WORKGROUP
security = user
interfaces = 192.168.1.107 127.0.0.1
bind interfaces only = yes
socket address = 192.168.1.255
printcap name = /dev/null
log level = 1
[Archive]
path = /mnt/pool/Archive
writeable = no
[ToArchive]
path = /mnt/pool/ToArchive
writeable = yesここでのポイントは[Archive]のwritableをnoにしておくこと。
設定ファイルを保存したらsmbを再起動。
sudo systemctl restart smb.service
SE Linux環境でsambaに特定フォルダへアクセスを許可する設定コマンド
sudo chcon -t samba_share_t /mnt/pool/ToArchive sudo chcon -t samba_share_t /mnt/pool/Archive
cronから実行するシェルスクリプト /home/thom/archive.sh
#!/bin/bash FILES="/mnt/pool/ToArchive/*" if [ -n "$(ls -A /mnt/pool/ToArchive/)" ];then for f in $FILES do echo "Processing: $f" /usr/local/bin/aws s3 cp $f s3://ここにS3バケット名/ --profile ここにユーザー名 mv $f /mnt/pool/Archive/ done else exit fi
crontab
*/1 * * * * /home/thom/archive.sh
関連のある過去記事
要改善点
同名の別ファイルをうっかりToArchiveに置いてしまうと恐らくアーカイブが上書きされてしまうので、バッチ処理にif文でArchiveに同じファイル名が存在するときは処理をしないか、あるいはArchiveErrorというフォルダを作ってそこに移動するか等考えたい。
これはさっさとやらないとまずそう。Redmineにタスク登録しておこう。
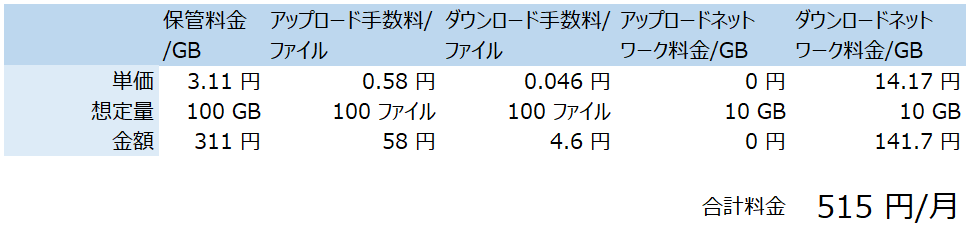
あと暗号化の仕組みもまだ導入できてない。
検証は以下の記事で終わってるので面倒くさがってるだけなんだけど、Redmineタスクには登録したので、近いうちに組み込みたいと思う。
thom.hateblo.jp

















![【改訂新版】サーバ構築の実例がわかるSamba[実践]入門](https://m.media-amazon.com/images/I/51zK0JJz6ZL._SL500_.jpg "【改訂新版】サーバ構築の実例がわかるSamba[実践]入門")