前回なんとか機械学習のスタートラインに付くことができた。
thom.hateblo.jp
その際に演習内容どおりに作ったのがこちら。

ただし演習をなぞって作っただけなので、これは動いて当たり前である。
これだとまだ私自身がスキルを身に着けてる感じがしないので、これを少し改造してみることにした。
今回は床を斜めにして滑りすくしてみる。ひとまず前回平坦な滑らない床で学習させたモデルを使って実験してみると、次のようになった。

なんとか耐えられるケースもあるけど、基本的にはポロポロと簡単にこぼれてしまう。
条件が変わったのに相変わらずTargetとの位置関係と自分のスピードしか見ておらず、以前と同様の基準で加減速するので当然の結果である。
なので、床の傾きも考慮して学習するように改造してみた。
UnityのGameObjectの変更
まずやることは、UnityのHierarchyウインドウでTargetとRollerAgentをFloorにドロップして子オブジェクトにしてしまう。
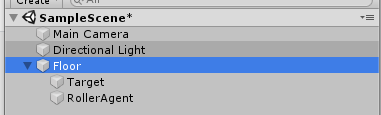
こうすると、TargetもRollerAgentもFloorを基準とした座標軸で動くことができる。Floorを傾けるとTargetもRollerAgentも一緒に傾く。
次にTargetにRigidbody(剛体)を付加。
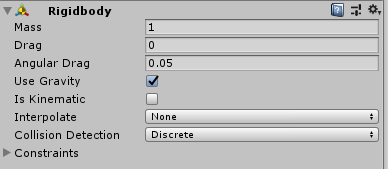
これをつけることで様々な物理法則の影響を受けるようになる。
あとPhysic Materialを作ってDynamic Frictionを0.05、Static Frictionを0.1に設定し、Floor・Target・RollerAgentにすべて設定した。

これはどれくらい滑るかという設定値で、0.05とか0.1とかは適当に調整しながらPlayして決めた。
次にRollerAgentのBehavior ParametersスクリプトのVectorObservationにあるSpace Sizeを12に増やす。
このとき演習で使った3DBallモデルは外しておく。

このSpace Sizeというのは観測する値の数を指していて、演習で8を指定するのは中身を次のように格納するためだ。
- Targetのx座標
- Targetのy座標
- Targetのz座標
- RollerAgentのx座標
- RollerAgentのy座標
- RollerAgentのz座標
- RollerAgentのx速度
- RollerAgentのz速度
実際に格納しているコードはこちら。

命令自体は4つしかないけど、最初の2つの命令はlocalPositionという3つのデータ(x, y, z)が入った型なので3,3,1,1で計8個である。
今回はFloorのlocalRotation情報を格納する。
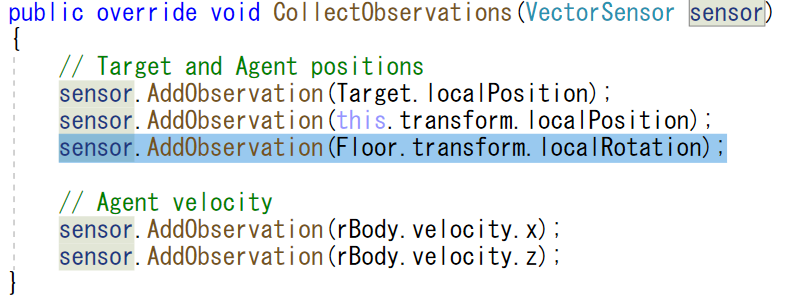
このlocalRotationの型は曲者で、Unity画面上のInspectorで見るとx, y, zの3軸なのに、実際にはx, y, z, wの4つの値が入るらしい。
それで8個から4つ増えて12個のデータが必要なのでSpace Sizeが12になる。
コードの修正
RollerAgent.csのコード全体は次のとおり。
日本語で「~を追加」とコメントしてるところが私が追加した部分である。
using System.Collections; using System.Collections.Generic; using UnityEngine; using Unity.MLAgents; using Unity.MLAgents.Sensors; using Unity.MLAgents.Actuators; public class RollerAgent : Agent { Rigidbody rBody; void Start() { rBody = GetComponent<Rigidbody>(); } public Transform Target; // フロアを参照させるためのTransform型変数を追加 public Transform Floor; public override void OnEpisodeBegin() { // If the Agent fell, zero its momentum if (this.transform.localPosition.y < 0) { this.rBody.angularVelocity = Vector3.zero; this.rBody.velocity = Vector3.zero; this.transform.localPosition = new Vector3(0, 0.5f, 0); } // Move the target to a new spot Target.localPosition = new Vector3(Random.value * 8 - 4, 0.5f, Random.value * 8 - 4); //最初にローテーションをリセットする処理を追加 Floor.transform.localRotation = new Quaternion(0,0,0,0); //-10°~10°の範囲でx軸・z軸をそれぞれランダムでローテートさせる処理を追加 Floor.transform.Rotate(Random.Range(-10f,10f), 0, Random.Range(-10f, 10f)); } public override void CollectObservations(VectorSensor sensor) { // Target and Agent positions sensor.AddObservation(Target.localPosition); sensor.AddObservation(this.transform.localPosition); //フロアのローテーション観察を追加 sensor.AddObservation(Floor.transform.localRotation); // Agent velocity sensor.AddObservation(rBody.velocity.x); sensor.AddObservation(rBody.velocity.z); } public float forceMultiplier = 10; public override void OnActionReceived(ActionBuffers actionBuffers) { // Actions, size = 2 Vector3 controlSignal = Vector3.zero; controlSignal.x = actionBuffers.ContinuousActions[0]; controlSignal.z = actionBuffers.ContinuousActions[1]; rBody.AddForce(controlSignal * forceMultiplier); // Rewards float distanceToTarget = Vector3.Distance(this.transform.localPosition, Target.localPosition); // Reached target if (distanceToTarget < 1.42f) { SetReward(1.0f); EndEpisode(); } // Fell off platform else if (this.transform.localPosition.y < 0) { EndEpisode(); } } public override void Heuristic(in ActionBuffers actionsOut) { var continuousActionsOut = actionsOut.ContinuousActions; continuousActionsOut[0] = Input.GetAxis("Horizontal"); continuousActionsOut[1] = Input.GetAxis("Vertical"); } }
Public変数「Floor」にGameObjectのFloorをドラッグして設定すると、学習の準備は完了。
学習させる。
演習と同じ要領で学習を開始する。
学習に使用するconfigファイル(yaml)は特に修正不要だが、run-idは使いまわしできないかと思うのでRollerBall2とした。
以下は学習中の様子。

前回平坦な床で学習させたとき、Mean Reward(平均報酬)はわずか20000ステップ(149秒)で0.991と達人級の学習能力を見せつけてくれた。
報酬は成功したら1、失敗したら0と設定しているため、平均0.991ということは概ね100回中99回は成功するという意味になる。
2021-01-23 19:57:06 INFO [stats.py:139] RollerBall. Step: 10000. Time Elapsed: 78.755 s. Mean Reward: 0.672. Std of Reward: 0.469. Training. 2021-01-23 19:58:16 INFO [stats.py:139] RollerBall. Step: 20000. Time Elapsed: 149.032 s. Mean Reward: 0.991. Std of Reward: 0.093. Training.
今回は以下のようなログになった。
2021-01-24 20:00:37 INFO [stats.py:139] RollerBall. Step: 10000. Time Elapsed: 79.503 s. Mean Reward: 0.371. Std of Reward: 0.483. Training. 2021-01-24 20:01:49 INFO [stats.py:139] RollerBall. Step: 20000. Time Elapsed: 150.908 s. Mean Reward: 0.661. Std of Reward: 0.473. Training. 2021-01-24 20:03:01 INFO [stats.py:139] RollerBall. Step: 30000. Time Elapsed: 222.803 s. Mean Reward: 0.791. Std of Reward: 0.406. Training. 2021-01-24 20:04:13 INFO [stats.py:139] RollerBall. Step: 40000. Time Elapsed: 295.321 s. Mean Reward: 0.767. Std of Reward: 0.423. Training. 2021-01-24 20:05:25 INFO [stats.py:139] RollerBall. Step: 50000. Time Elapsed: 367.443 s. Mean Reward: 0.777. Std of Reward: 0.416. Training. 2021-01-24 20:06:37 INFO [stats.py:139] RollerBall. Step: 60000. Time Elapsed: 439.412 s. Mean Reward: 0.764. Std of Reward: 0.425. Training. 2021-01-24 20:07:49 INFO [stats.py:139] RollerBall. Step: 70000. Time Elapsed: 510.808 s. Mean Reward: 0.733. Std of Reward: 0.443. Training. 2021-01-24 20:08:59 INFO [stats.py:139] RollerBall. Step: 80000. Time Elapsed: 581.359 s. Mean Reward: 0.774. Std of Reward: 0.418. Training. 2021-01-24 20:10:10 INFO [stats.py:139] RollerBall. Step: 90000. Time Elapsed: 652.560 s. Mean Reward: 0.779. Std of Reward: 0.415. Training. 2021-01-24 20:11:23 INFO [stats.py:139] RollerBall. Step: 100000. Time Elapsed: 725.470 s. Mean Reward: 0.751. Std of Reward: 0.433. Training. 2021-01-24 20:12:37 INFO [stats.py:139] RollerBall. Step: 110000. Time Elapsed: 799.360 s. Mean Reward: 0.794. Std of Reward: 0.404. Training. 2021-01-24 20:13:52 INFO [stats.py:139] RollerBall. Step: 120000. Time Elapsed: 874.147 s. Mean Reward: 0.791. Std of Reward: 0.406. Training. 2021-01-24 20:15:06 INFO [stats.py:139] RollerBall. Step: 130000. Time Elapsed: 948.227 s. Mean Reward: 0.797. Std of Reward: 0.402. Training. 2021-01-24 20:16:20 INFO [stats.py:139] RollerBall. Step: 140000. Time Elapsed: 1022.675 s. Mean Reward: 0.852. Std of Reward: 0.355. Training. 2021-01-24 20:17:33 INFO [stats.py:139] RollerBall. Step: 150000. Time Elapsed: 1095.735 s. Mean Reward: 0.885. Std of Reward: 0.319. Training. 2021-01-24 20:18:47 INFO [stats.py:139] RollerBall. Step: 160000. Time Elapsed: 1169.150 s. Mean Reward: 0.875. Std of Reward: 0.330. Training. 2021-01-24 20:20:01 INFO [stats.py:139] RollerBall. Step: 170000. Time Elapsed: 1243.355 s. Mean Reward: 0.901. Std of Reward: 0.298. Training. 2021-01-24 20:21:15 INFO [stats.py:139] RollerBall. Step: 180000. Time Elapsed: 1317.187 s. Mean Reward: 0.904. Std of Reward: 0.295. Training. 2021-01-24 20:22:28 INFO [stats.py:139] RollerBall. Step: 190000. Time Elapsed: 1390.495 s. Mean Reward: 0.908. Std of Reward: 0.289. Training. 2021-01-24 20:23:41 INFO [stats.py:139] RollerBall. Step: 200000. Time Elapsed: 1463.643 s. Mean Reward: 0.891. Std of Reward: 0.312. Training. 2021-01-24 20:24:55 INFO [stats.py:139] RollerBall. Step: 210000. Time Elapsed: 1536.943 s. Mean Reward: 0.907. Std of Reward: 0.290. Training. 2021-01-24 20:26:08 INFO [stats.py:139] RollerBall. Step: 220000. Time Elapsed: 1610.528 s. Mean Reward: 0.907. Std of Reward: 0.290. Training. 2021-01-24 20:27:21 INFO [stats.py:139] RollerBall. Step: 230000. Time Elapsed: 1683.587 s. Mean Reward: 0.898. Std of Reward: 0.303. Training. 2021-01-24 20:28:37 INFO [stats.py:139] RollerBall. Step: 240000. Time Elapsed: 1758.921 s. Mean Reward: 0.903. Std of Reward: 0.297. Training. 2021-01-24 20:29:50 INFO [stats.py:139] RollerBall. Step: 250000. Time Elapsed: 1832.258 s. Mean Reward: 0.893. Std of Reward: 0.309. Training. 2021-01-24 20:31:04 INFO [stats.py:139] RollerBall. Step: 260000. Time Elapsed: 1905.822 s. Mean Reward: 0.909. Std of Reward: 0.288. Training. 2021-01-24 20:32:17 INFO [stats.py:139] RollerBall. Step: 270000. Time Elapsed: 1979.798 s. Mean Reward: 0.895. Std of Reward: 0.306. Training. 2021-01-24 20:33:31 INFO [stats.py:139] RollerBall. Step: 280000. Time Elapsed: 2053.540 s. Mean Reward: 0.872. Std of Reward: 0.334. Training. 2021-01-24 20:34:45 INFO [stats.py:139] RollerBall. Step: 290000. Time Elapsed: 2127.722 s. Mean Reward: 0.880. Std of Reward: 0.325. Training. 2021-01-24 20:35:59 INFO [stats.py:139] RollerBall. Step: 300000. Time Elapsed: 2201.468 s. Mean Reward: 0.861. Std of Reward: 0.346. Training. 2021-01-24 20:37:13 INFO [stats.py:139] RollerBall. Step: 310000. Time Elapsed: 2275.476 s. Mean Reward: 0.868. Std of Reward: 0.339. Training. 2021-01-24 20:38:28 INFO [stats.py:139] RollerBall. Step: 320000. Time Elapsed: 2350.178 s. Mean Reward: 0.864. Std of Reward: 0.343. Training. 2021-01-24 20:39:42 INFO [stats.py:139] RollerBall. Step: 330000. Time Elapsed: 2423.811 s. Mean Reward: 0.854. Std of Reward: 0.353. Training. 2021-01-24 20:40:55 INFO [stats.py:139] RollerBall. Step: 340000. Time Elapsed: 2497.704 s. Mean Reward: 0.828. Std of Reward: 0.378. Training. 2021-01-24 20:42:13 INFO [stats.py:139] RollerBall. Step: 350000. Time Elapsed: 2575.427 s. Mean Reward: 0.844. Std of Reward: 0.363. Training. 2021-01-24 20:43:28 INFO [stats.py:139] RollerBall. Step: 360000. Time Elapsed: 2650.043 s. Mean Reward: 0.811. Std of Reward: 0.392. Training. 2021-01-24 20:44:42 INFO [stats.py:139] RollerBall. Step: 370000. Time Elapsed: 2724.516 s. Mean Reward: 0.799. Std of Reward: 0.401. Training. 2021-01-24 20:45:59 INFO [stats.py:139] RollerBall. Step: 380000. Time Elapsed: 2801.075 s. Mean Reward: 0.804. Std of Reward: 0.397. Training. 2021-01-24 20:47:17 INFO [stats.py:139] RollerBall. Step: 390000. Time Elapsed: 2879.487 s. Mean Reward: 0.851. Std of Reward: 0.356. Training. 2021-01-24 20:48:34 INFO [stats.py:139] RollerBall. Step: 400000. Time Elapsed: 2956.177 s. Mean Reward: 0.851. Std of Reward: 0.357. Training. 2021-01-24 20:49:49 INFO [stats.py:139] RollerBall. Step: 410000. Time Elapsed: 3031.613 s. Mean Reward: 0.861. Std of Reward: 0.346. Training. 2021-01-24 20:51:04 INFO [stats.py:139] RollerBall. Step: 420000. Time Elapsed: 3106.688 s. Mean Reward: 0.872. Std of Reward: 0.334. Training. 2021-01-24 20:52:18 INFO [stats.py:139] RollerBall. Step: 430000. Time Elapsed: 3180.005 s. Mean Reward: 0.870. Std of Reward: 0.336. Training. 2021-01-24 20:53:37 INFO [stats.py:139] RollerBall. Step: 440000. Time Elapsed: 3258.956 s. Mean Reward: 0.854. Std of Reward: 0.354. Training. 2021-01-24 20:54:53 INFO [stats.py:139] RollerBall. Step: 450000. Time Elapsed: 3335.078 s. Mean Reward: 0.886. Std of Reward: 0.318. Training. 2021-01-24 20:56:08 INFO [stats.py:139] RollerBall. Step: 460000. Time Elapsed: 3410.529 s. Mean Reward: 0.905. Std of Reward: 0.294. Training. 2021-01-24 20:57:22 INFO [stats.py:139] RollerBall. Step: 470000. Time Elapsed: 3484.081 s. Mean Reward: 0.888. Std of Reward: 0.316. Training. 2021-01-24 20:58:36 INFO [stats.py:139] RollerBall. Step: 480000. Time Elapsed: 3558.386 s. Mean Reward: 0.879. Std of Reward: 0.326. Training. 2021-01-24 20:59:49 INFO [stats.py:139] RollerBall. Step: 490000. Time Elapsed: 3630.810 s. Mean Reward: 0.880. Std of Reward: 0.325. Training. 2021-01-24 21:01:03 INFO [stats.py:139] RollerBall. Step: 500000. Time Elapsed: 3705.281 s. Mean Reward: 0.887. Std of Reward: 0.317. Training.
既定の学習回数50万回を経ても、よくて9割といったところ。要は10回に1回くらいは落ちる。
今回は箱自体が滑り落ちるので、場所が悪いと落ちる箱を追い続けて玉も必然的に落ちるというパターンも多くあった。
推論の実行結果
学習したモデルをAgentのBehavior ParametersのModelに指定し、実際に推論によって操作させてみたのがこちら。

落ちるときは落ちるけどそれなりにうまく立ち回っている。
「まぁ所詮こんなもんかな」という感想だったんだけど、試しに私が操作してみた。
↓私の操作
すみませんでしたぁぁぁ。
以上。