今回はAmazon AWSのS3ストレージサービスを活用して重要なファイルをクラウドにアーカイブしてみる。
アーカイブとは
バックアップとアーカイブの違いは、日常的に更新するかどうかである。
例えばWindows10には標準でOneDriveが付いてくるので、ここに入れておけばハードディスクが故障してもクラウド上にファイルは残る。そういう意味でクラウドバックアップは既に普段使いしていると言える。
ただ、ユーザー操作のミスでファイルを書き換えてしまったり消してしまった場合はクラウド上でもそうした操作が同期されてデータが消失するリスクが残る。
したがって、更新はしないけど無くなると困る重要なファイルは、どこか別のところに避けておきたい。
これが基本的なアーカイブの考え方である。大切な思い出の写真とかが分かりやすい例かなと思う。
Amazon AWS S3とは
AWS S3は低価格なストレージサービスで、バケット(要するにバケツ)という場所にファイルをどんどん放り込んでいくという使い方をする。一般的なファイルシステムのようにフォルダーで整理するということは想定されておらず、とにかく一個所にファイルを放り込んでいくイメージ。またデフォルトで3か所のデータセンターにデータが保存されるのでデータの耐久性は99.999999999%(イレブンナイン)。今回のアーカイブ用途にはうってつけだ。
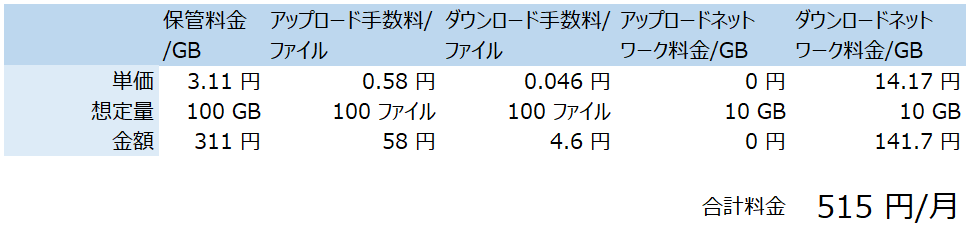
料金表はこちら。
aws.amazon.com
多く見積もって最大で100GB保管する想定で計算してみたところ、月額515円と個人でも十分支払い可能な料金である。(22年4月10日現在の為替レートによる)
※情報が間違っていても責任は負いかねるので実際に活用される方は自己責任で。
※S3ストレージが安いだけで、他のAWSサービスは普通に高いので注意。特にインターネットで一般公開するようなサーバーはアクセス量が予測できないのでちゃんと調べて計算しないと怖い印象。
実際に設定してみる
※AWSのアカウント取得とかは割愛。
※ここで紹介するのは私がこうやったという手順なので、適切かどうかは保証しない。
アクセスユーザーの作成
まずサービスメニューからIAMを開く

IAMというのはIdentity and Access Managementの略で、要はIDとアクセス権限の管理。
ユーザーメニューからユーザーを追加をクリック
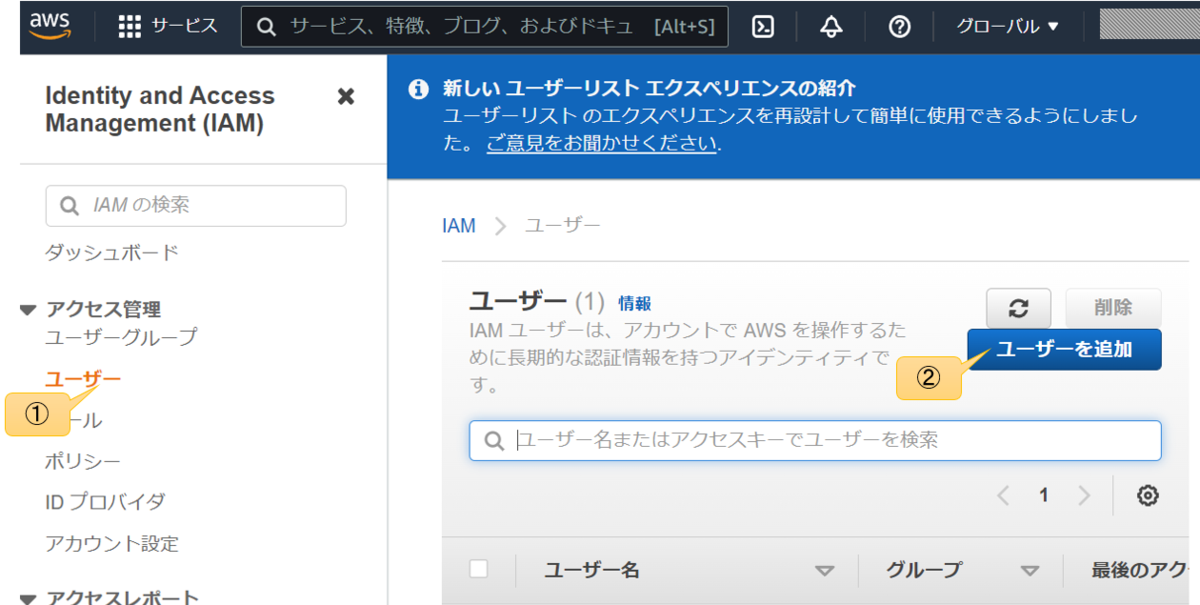
ユーザー名を決めて、アクセスキー・プログラムによるアクセスにチェックを入れて次のステップへ
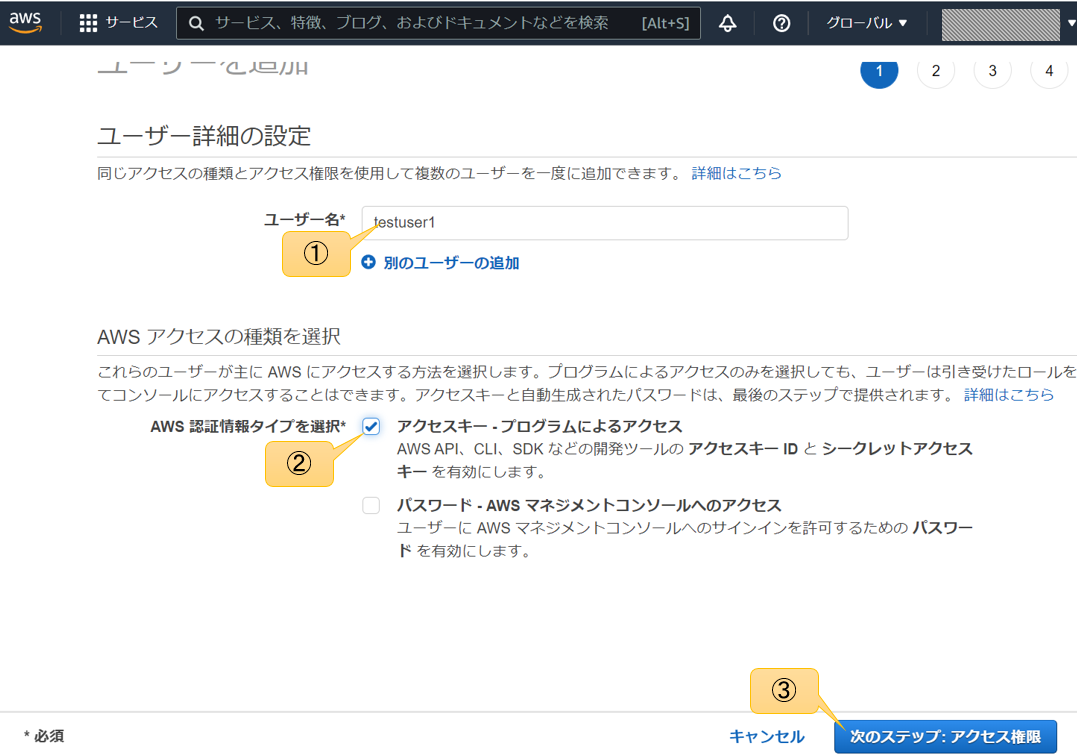
既存ポリシー直接アタッチを選択してs3を検索、出てきたAmazonS3FullAccessを選択して次のステップへ
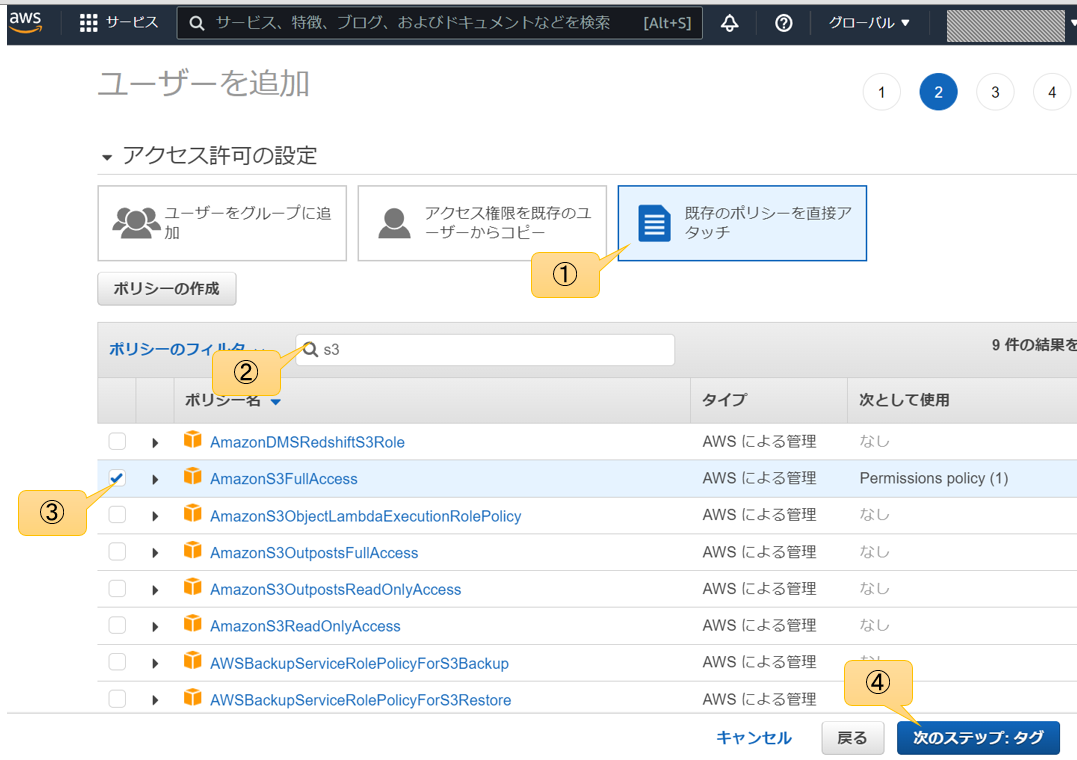
タグは特に要らないのでそのまま次のステップへ
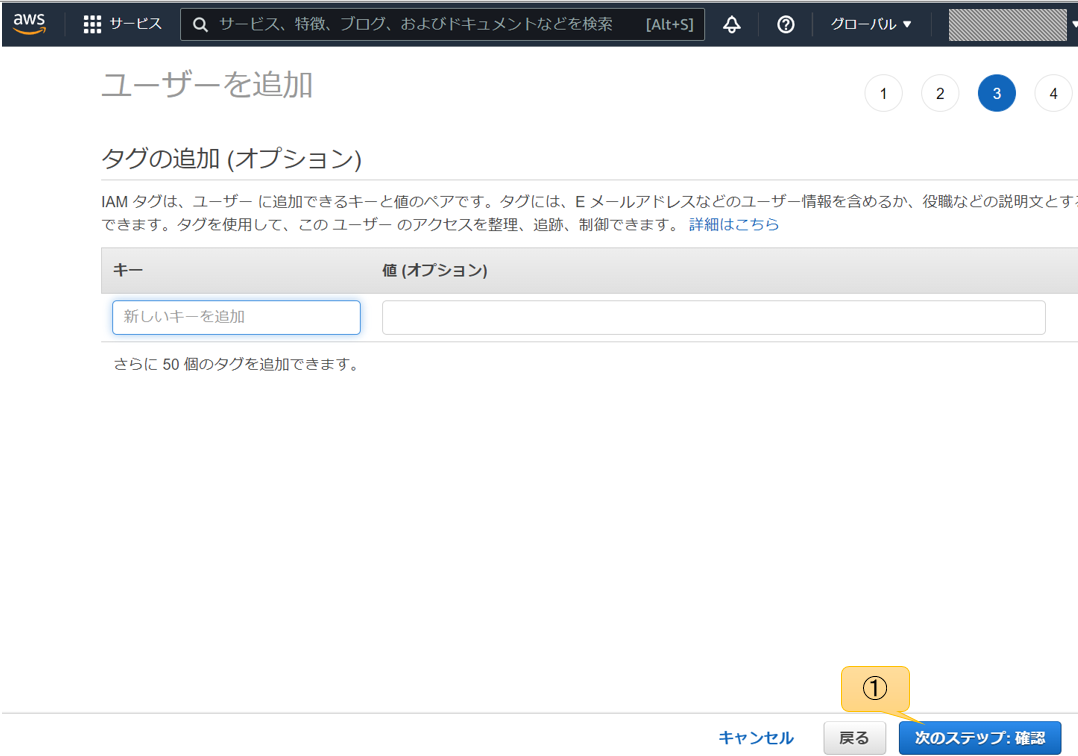
確認画面で問題なければユーザーの作成をクリック
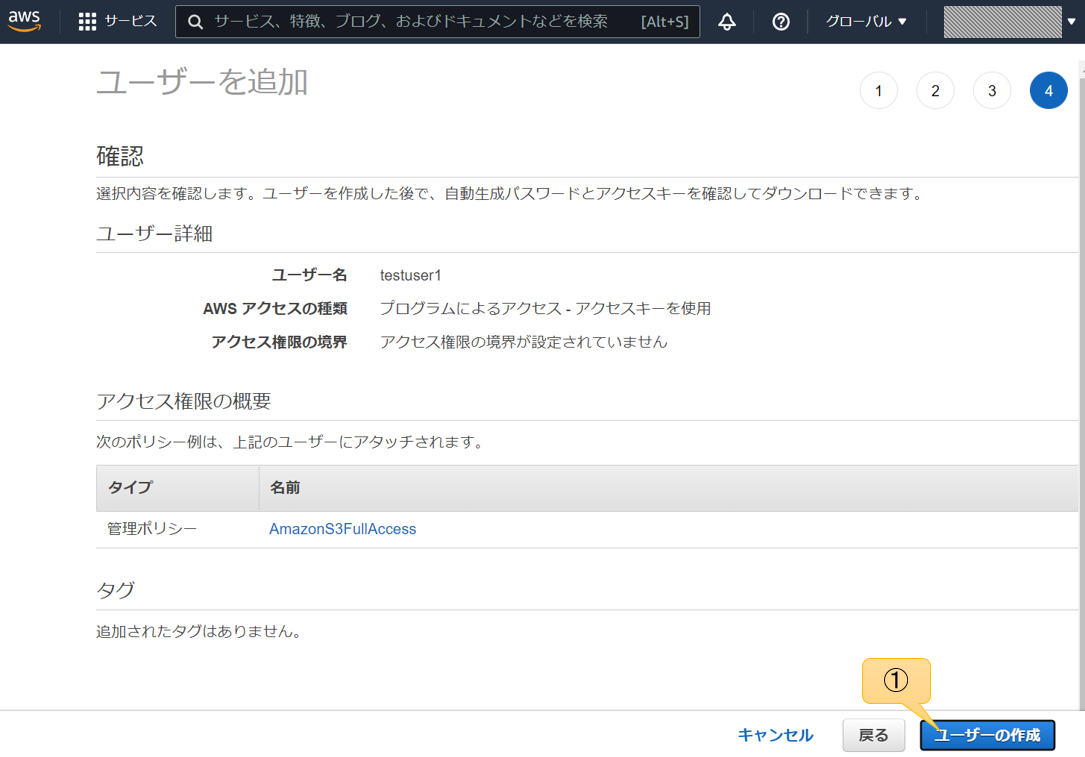
アクセスキーとシークレットアクセスキーを控えておく
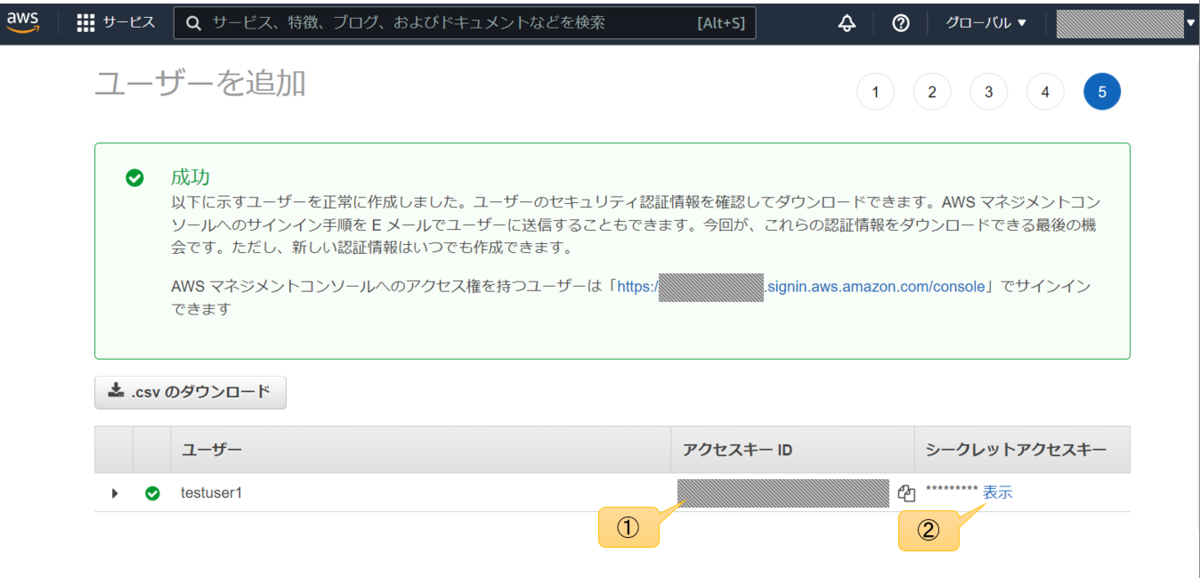
以上でユーザー作成は完了
S3ストレージの開設
サービスメニューからS3を開く
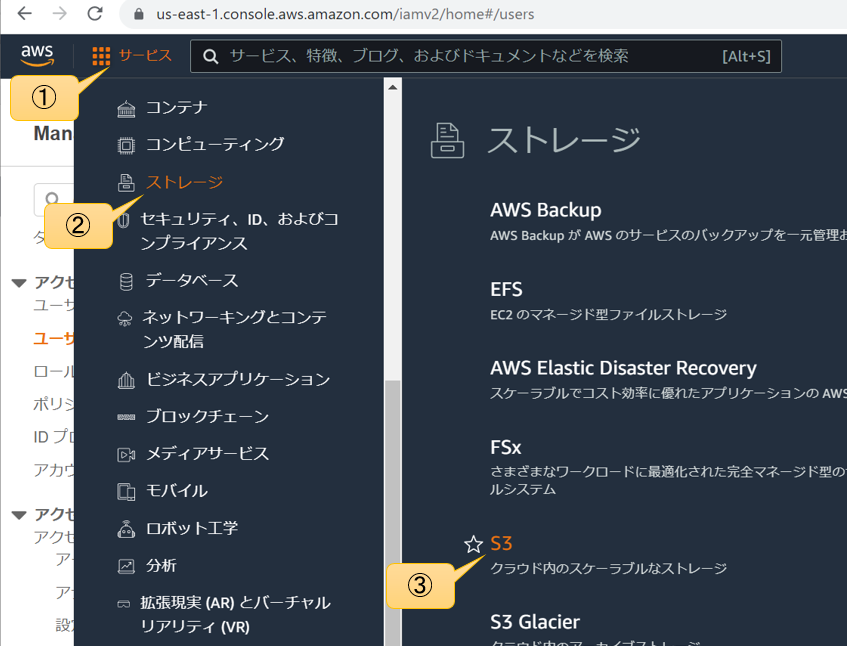
バケットメニューからバケットを作成する
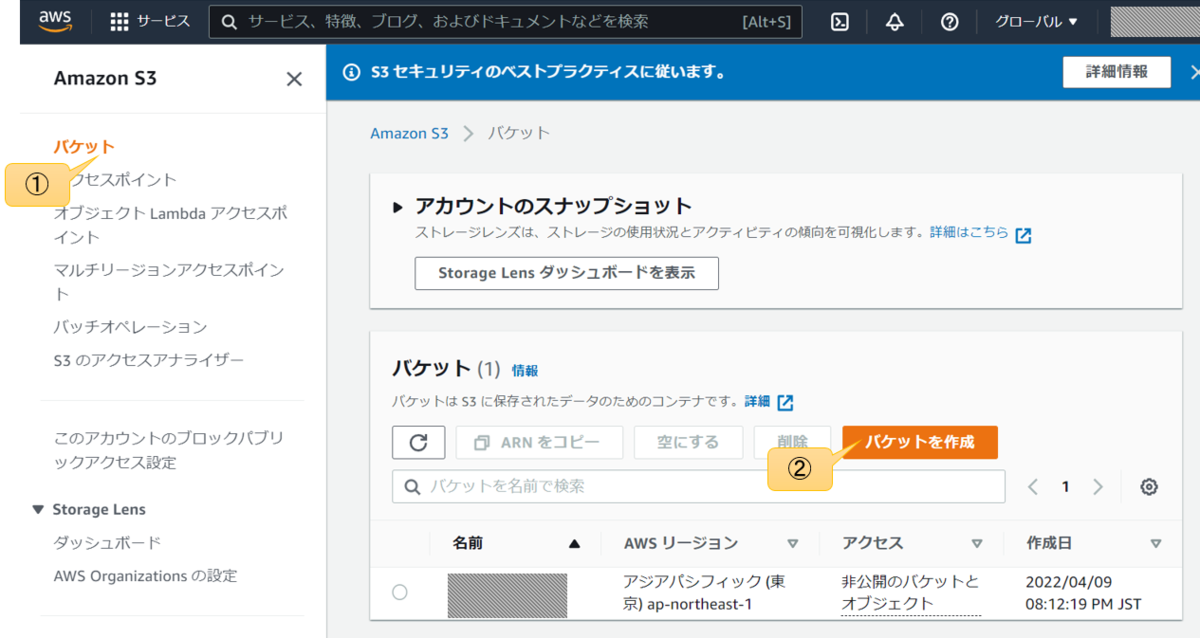
バケット名とリージョンを選択した後、下のほうにスクロールして作成をクリック
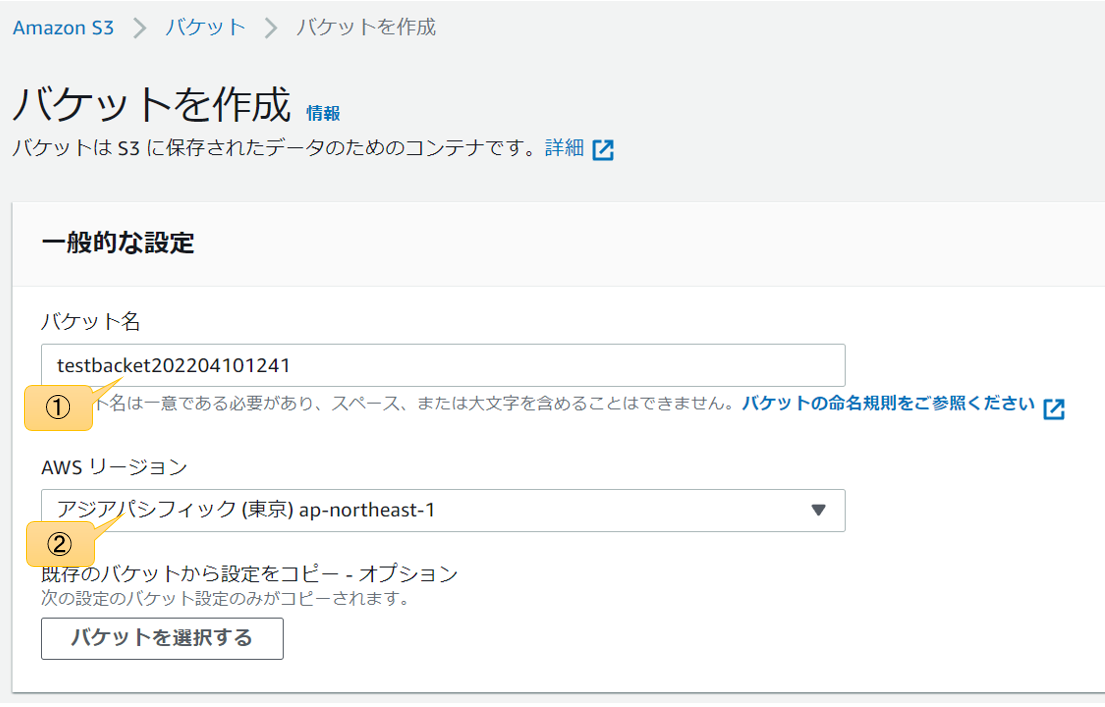
バケット名は他人とも被ってはいけないらしい。
とりあえずテストで作る場合は日付時刻を入れると被る可能性が極めて低いのでおススメ。
S3のリージョンはローカルにもコピーを持つ前提で災害対策を考えるなら自分が住んでる地域とは少し離れてる方が理想。私は関西住まいなので東京リージョンを選択した。
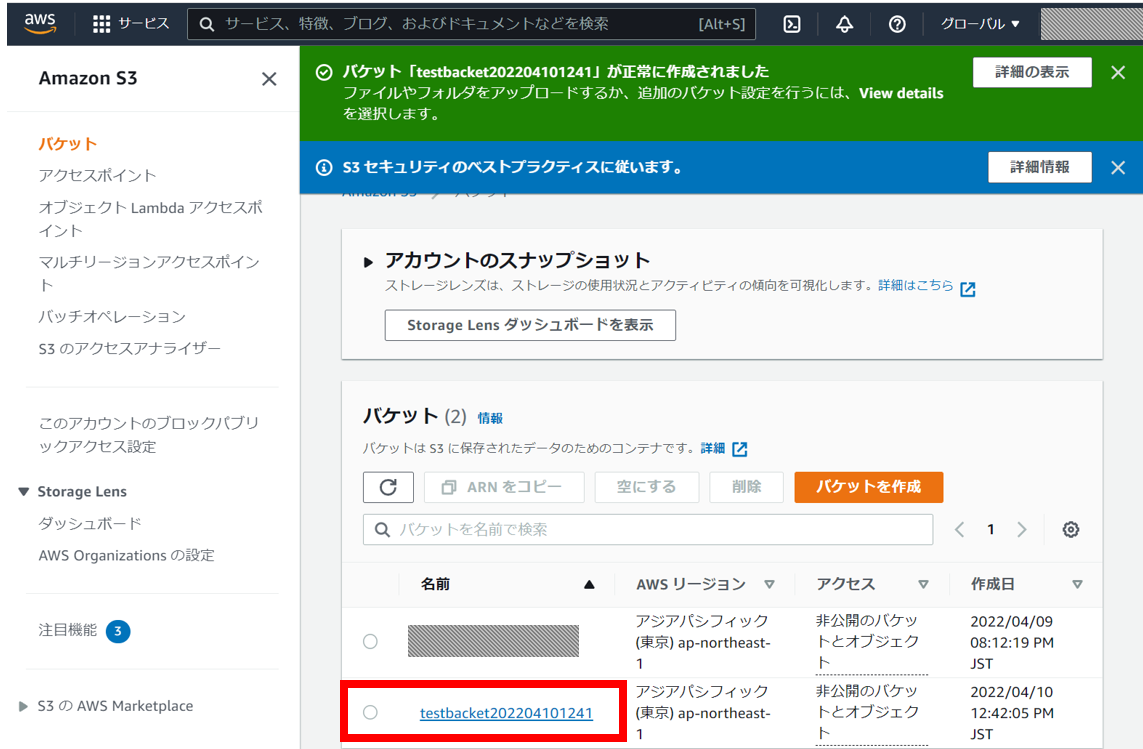
これで、Linuxにインストールするawsのクライアントからは「s3://testbacket202204101241/」としてアクセスできるようになる。
また、このページからブラウザ上でのアップロード・ダウンロード・削除などの操作も可能。
Linux上の設定 (CentOS 7の場合)
CentOS 7の場合は次のようにしてpython3とawscliをインストール
sudo yum update sudo yum install python3 sudo pip3 install awscli
awscliの接続設定を行う
aws configure --profile AWSのIAMで作ったユーザー名 と入力するとアクセスキー、シークレットキー、デフォルトリージョン名、出力フォーマットを聞かれるので順次入力する。つぎに環境変数でデフォルトプロファイルに設定。
aws configure --profile testuser1 # 上記を実行すると以下4点が順番に質問される。 AWS Access Key ID [None]: ここにさっき控えたアクセスキーを張る AWS Secret Access Key [None]: ここにさっき控えたシークレットアクセスキーを張る Default region name [None]: ap-northeast-1 Default output format [None]: json # 今作ったプロファイルをデフォルトに指定 export AWS_DEFAULT_PROFILE=testuser1
以上で使う準備が完了。
使用方法
Linux上でアップロードしたいファイルを指定する。
# aws s3 cp アップロードしたいファイル s3://バケットのパス/ aws s3 cp test.jpg s3://testbacket202204101241/
あとはブラウザからAWSのS3にアクセスしてバケットを覗くとちゃんとデータが入ってるのが分かる。
AWSを初めて触る方にオススメの書籍
あんまり重たい書籍だと途中で嫌になるけど、以下の書籍はさくっと読めて概念を理解するのにちょうどよかった。

この記事で書いたような具体的な手順は解説されていないが、参考URLが書かれているのでそこまで困らないと思う。
ただしある程度のインフラ知識が前提なので、IT未経験ですという人に向けた書籍ではない。
基本情報技術者程度の知識か、もしくは自分でオンプレミスのサーバー運用経験があればよく理解できると思う。
以上